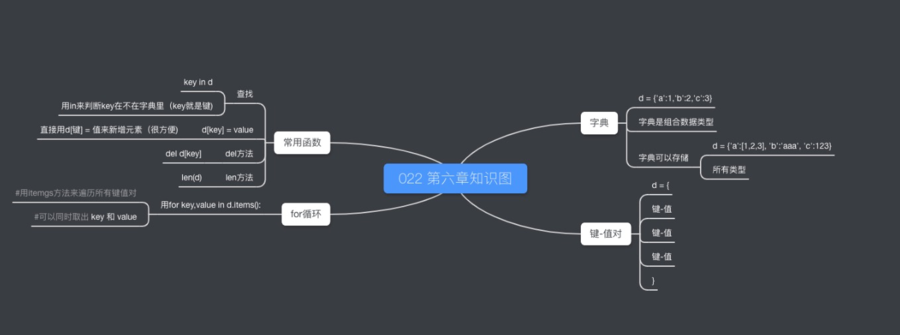
本章知识点 :> 字典
- 本章介绍的是
字典,字典也是一种组合数据类型,跟列表只有一个不同点(几乎就是孪生兄弟) - 现在我们一边复习列表的操作,一遍讲对应的字典操作
字典与列表
- 假设现在有一本中英文对照字典,内容包括
("你好" - 'hello')("中国" - 'china')("生活" - ’life')("男孩" - ‘boy’)... ... - 这样的一对对的词组
思考:用list怎么存储这个中英文字典呢?(要考虑后面用中文去查找对应的英文)
思路1:用两个列表,一个存储中文,一个存储英文(用下标1-1对应)
思路2:用一个列表,每一个元素还是一个列表(存储中英文对)
直接用列表来存储这个字典,都无法直接通过中文找到英文(需要先找到下标,再找到英文)
字典(Python里的字典类型)则可以直接通过中文找到英文看一下:
语法是这样的:

易错点:用
[ ]表示列表; 用{}表示字典- 易错点:关键是理解
键, 在列表里,用0,1,2,3来表示变量的位置(还记得吗);在字典里,用“中国” , 1, "abc"
来表示变量的key(也就是键) - 在列表里这样访问数据,
list[1] list[0]字典里d["a"] d["中国"] - 易错点:在列表里的变量可以是不同类型;字典里也一样
list1 = ["你好","中国","生活","男孩"]list2 = ['hello','china',’life',‘boy’]list = [["你好" , 'hello'],["中国" , 'china'],["生活" , ’life'],["男孩" , ‘boy’]]
字典访问
- 列表访问
list1 = ["你好","中国","生活","男孩"]
list2 = ['hello','china',’life',‘boy’]
i = list.index('中国')
list2[i] #结果为hello
- 字典访问
字典函数
如何判断一个元素在列表里
如何判断一个元素在字典里
易错点:在字典的判断,直接用
x in dict的语法即可len函数 可以用在列表和字典上
添加元素(字典更加方便), 比如:添加一对单词
('女孩' - 'girl')del 可以用于列表和字典的删除元素
list1 = ["你好","中国","生活","男孩"]list2 = ['hello','china',’life',‘boy’]i = list.index('中国')if i >=0:print("在")试一下 在线Python
d = {"你好" : 'hello',"中国" : 'china',"生活" : ’life',"男孩" : ‘boy’}if ‘中国' in d:print("在")试一下 在线Python
for 循环
list = [1,2,3,4,5]
for i in list:
print(i)
试一下 在线Python
- 这是一个列表遍历算法
- 字典的遍历非常类似
d = {
"你好" : 'hello',
"中国" : 'china',
"生活" : ’life',
"男孩" : ‘boy’
}
for ch,en in d.items():
print(ch + '-->' + en)
试一下 在线Python
- 注意用
d.items()函数取出所有键-值对 - 没有办法,
列表和字典就是这么形影不离,如果我们可以对照着理解,就会特别好记!
###### 单词计数
- 现在看一个实际问题,我们也理一理思路
- 经典的单词计数问题,现在有一篇文章,请你写一个Python程序来计算每一个单词的出现次数(假设用aa bb来代表单词)
aa bb aa cc dd
aa bb cc aa ee
ff gg hh
jj ff gg
ee ss
- 思考一下:我们用什么来存储这篇文章?
- 思考一下:我们用什么存储计数?
list = ['aa', 'bb']
d = {'aa':0, 'bb':0}
- 我分别用list 和 d 来存储数据和计数(一个是列表,一个是字典)
- 思路:显然要用循环
- 重复的事:遍历list取每一个单词 word
在d里面把word对应的计数+1
还考虑写一个函数 取名
wordcount- 输入:
list - 输出:
d
def wordcount(list): ( 还记得函数吗?)
d = {}
#..
return d

- 实现如下:
list = ['aa' , 'bb' ,'aa' ,'cc' ,'dd',
'aa' ,'bb' ,'cc', 'aa', 'ee',
'ff' ,'gg' ,'hh' ,
'jj' ,'ff', 'gg',
'ee' ,'ss']
def wordcount(list):
d = {}
for word in list:
is_in = word in d
if is_in == False:
d[word] = 0
d[word] = d[word] + 1
return d
word in d来判断是否存在###### 综合运用
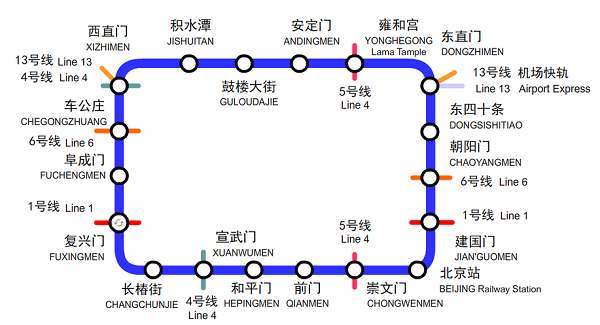
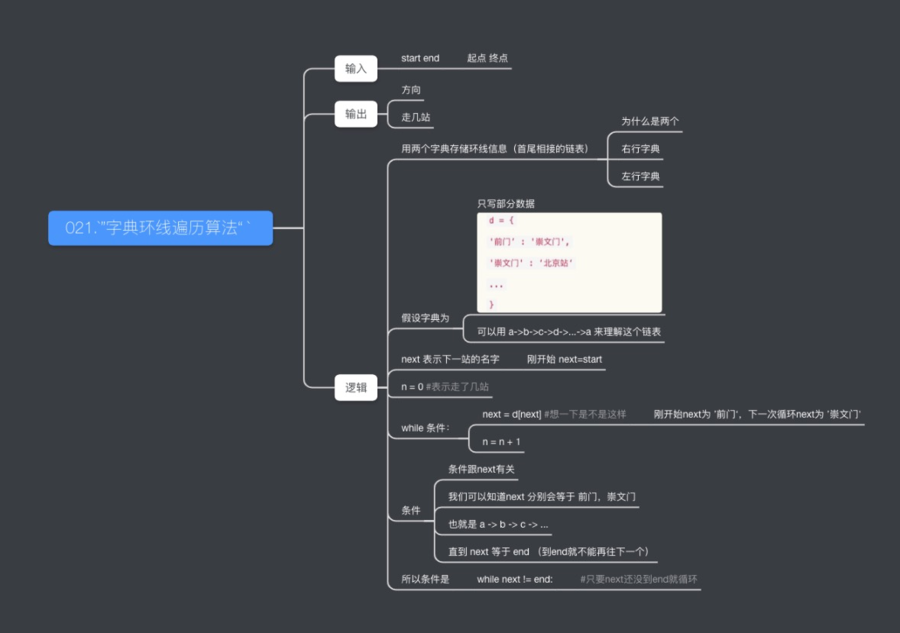
- 问题:请为地铁2号线,编写问路程序 (要求指出最优路线)
- 思路:先取名
环线最优路径算法 - 输入:
startend输出fangxiangzou_num 代码块定义成函数:
def huanxian(start, end):
fangxiang = ''
zou_num = 0
#待实现
return (fangxiang,zou_num) #可以同时返回两个变量哦~
- 现在考虑用字典存储 2号线环形信息。(键值对为
当前站名-下一站名) - 比如:
- 知道了 start 和 end 能不能在字典里找到路径?(思考一下)
- 大概的思路:循环取字典里的值,再将值作为键,找到下一站(也就是一站站往后循环)
d = {'前门’ : '崇文门','崇文门' : ‘北京站‘...}start = '前门'
next = start
next = d[next]
next = d[next]
试一下 在线Python
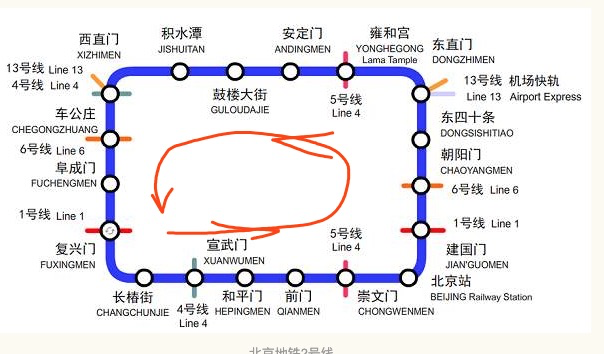
思路
- 实现以下环线算法
def huanxian(start, end):
fangxiang = ''
zou_num = 0
right_d = {'前门':'崇文门','崇文门’:'北京站','北京站':'建国门','建国门’:'朝阳门','朝阳门':'东四十条','东四十条’:'东直门','东直门':'雍和宫','雍和宫’:'安定门','安定门':'鼓楼大街','鼓楼大街’:'积水潭','积水潭':'西直门','西直门’:'车公庄', '车公庄':'阜成门','阜成门':'复兴门','复兴门':'长椿街','长椿街':'和平门','和平门':'前门'} #右行字典
left_d = {'崇文门':'前门','北京站':'崇文门’,'建国门':'北京站','朝阳门':'建国门’,'东四十条':'朝阳门','东直门':'东四十条’,'雍和宫':'东直门','安定门':'雍和宫’,'鼓楼大街':'安定门','积水潭':'鼓楼大街’,'西直门':'积水潭','车公庄':'西直门’, '阜成门':'车公庄','复兴门':'阜成门','长椿街':'复兴门','和平门':'长椿街','前门':'和平门'} #左行字典
#环线最优路径算法
next = start
right_n = 0 #先尝试右行
while next != end:
next = right_d[next] #下一站
right_n = right_n +1 #走了几站
next = start
left_n = 0 #尝试左行
while next != end:
next = left_d[next] #下一站
left_n = left_n +1 #走了几站
if right_n < left_n:
fangxiang = '右‘
zou_num = right_n
if left_n < right_n:
fangxiang = '左‘
zou_num = left_n
return (fangxiang, zou_num)
试一下 在线Python
- ”当前站回答法"
def say_dangqian():
print("现在出站")
- "问路回答法"
def huida(fangxiang, zou_num):
#待实现
a = 0
while a < zou_num:
print(fangxiang+'走1站') #一定要4个空格
a = a + 1
- 现在来写主程序( 特别短,很好读)
start = '?' #具体执行时填写
end = '?' #具体执行时填写
fangxiang = ''
zou_num = 0
if start == end:
say_dangqian()
(fangxiang,zou_num) = huanxian(start_num, end_num)
huida(fangxiang, zou_num)
下一章会先复习 字典 的知识,不用担心今天的新知识太多~
p6 知识点总结: